







PaddleOCR-VL是什么?
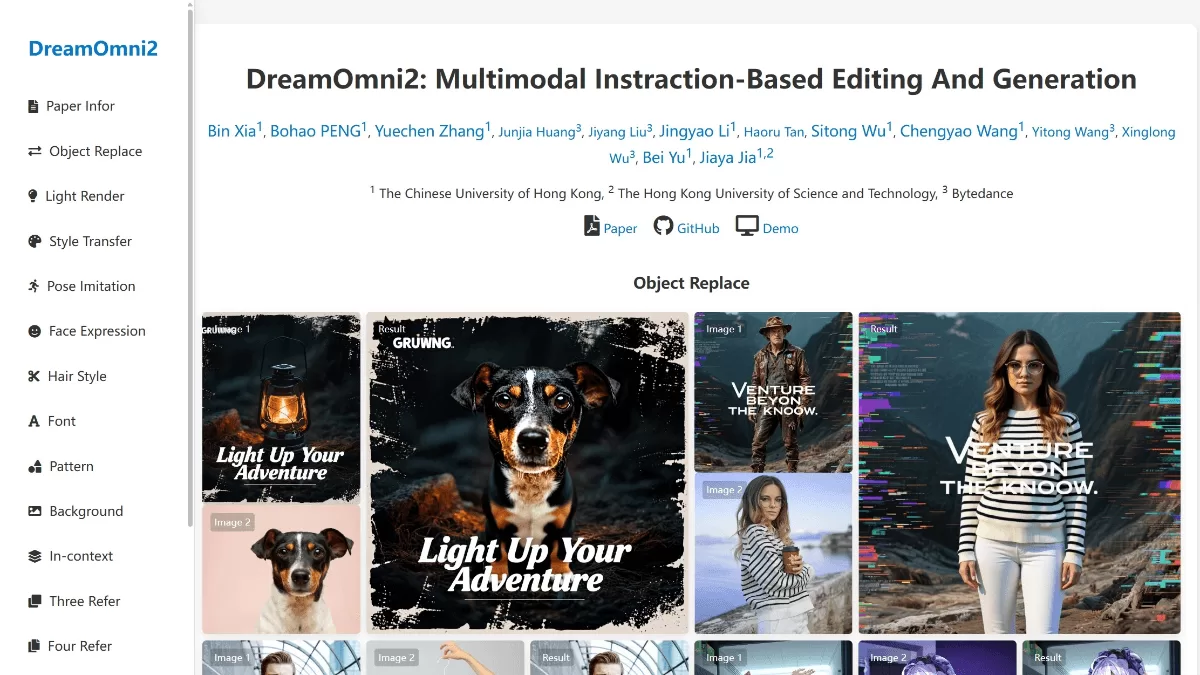
PaddleOCR-VL是百度研发的一款超轻量级视觉-语言模型,专门针对文档解析场景进行优化。该模型仅包含0.9B参数量,通过整合动态高分辨率视觉编码器与轻量级ERNIE语言模型,在维持高准确率的同时大幅降低了计算成本。支持109种语言,能够精确识别文本、表格、公式、图表等复杂元素,并呈现符合人类阅读习惯的版面布局。在权威基准测试OmniDocBench v1.5中,该模型以92.6分的优异成绩获得全球综合性能第一名,在文本编辑距离(0.035)、公式识别(CDM 91.43)、表格处理(TEDS 93.52)等关键指标上均达到当前最佳水平,超越了GPT-4o等主流多模态模型。

PaddleOCR-VL的功能特色
- 极致轻量与高效性能:参数量仅0.9B,可在普通CPU环境下运行,支持浏览器插件式部署,推理速度比同类模型快14.2%(对比MinerU2.5)和253.01%(对比dots.ocr)。
- 多元素精准解析:能够识别文本、表格、公式、图表等复杂文档元素,在权威评测中中文本编辑距离为0.035,公式识别CDM达到91.43,表格TEDS达到93.52,均处于行业领先地位。
- 多语言与复杂场景适配:覆盖109种语言(含俄语、阿拉伯语等特殊书写体系),擅长处理手写体、历史文献及垂直排版文本(如中文竖排),满足全球化的文档处理需求。
- 智能版面分析与阅读顺序还原:采用两阶段架构(PP-DocLayoutV2版面检测+PaddleOCR-VL-0.9B识别),自动预测阅读逻辑,阅读顺序误差仅0.043,精准还原人类阅读习惯。
- 开源与实战优势:完全开源并提供Demo,在发票识别、学术论文解析等场景表现突出,可与RAG系统结合,成为AI知识处理基础设施。
PaddleOCR-VL的核心优势
- 极致轻量化与高效推理:核心模型参数量控制在0.9B,普通CPU即可运行,支持浏览器插件部署,内存占用极低。单张A100 GPU上推理速度比MinerU2.5快14.2%,比dots.ocr快253.01%,显著降低计算成本。
- 多语言与复杂元素精准识别:支持109种语言,涵盖中文、英语、阿拉伯语、俄语等特殊书写体系,能精准处理文本、表格、公式、图表、手写体及历史文档等复杂元素。
- 两阶段架构稳定可靠:采用PP-DocLayoutV2版面检测 + PaddleOCR-VL-0.9B内容识别的协同框架,有效避免端到端模型常见的幻觉与错位问题,在复杂版面中表现更稳定。
- 多模态深度融合与真实理解:通过NaViT动态分辨率视觉编码器与ERNIE-4.5-0.3B语言模型结合,实现从字符识别到语义理解的全面突破,智能处理多栏排版、数学公式、二维码等特殊元素。
- 权威评测性能领先:在OmniDocBench V1.5等权威榜单中综合性能排名全球第一,超越Gemini-2.5 Pro、GPT-4o等巨型多模态模型,以及垂直领域模型dots.ocr、MinerU等。
PaddleOCR-VL官网是什么
- 项目官网:https://ernie.baidu.com/blog/zh/posts/paddleocr-vl/
- HuggingFace模型库:https://huggingface.co/PaddlePaddle/PaddleOCR-VL
- arXiv技术论文:https://arxiv.org/pdf/2510.14528
- 在线体验Demo:https://huggingface.co/spaces/PaddlePaddle/PaddleOCR-VL_Online_Demo
- 官方体验地址:https://aistudio.baidu.com/application/detail/98365
PaddleOCR-VL的适用人群
- 开发者与工程师:需要集成OCR功能的软件开发者,特别适合资源受限场景(如浏览器插件、移动端应用)和开源社区协作。
- 企业IT与数字化团队:金融、零售、制造等行业中需要处理大量文档的企业,用于构建自动化流程(如合同审核、库存管理)。
- 研究人员与教育工作者:学术机构、图书馆及教育行业从业者,用于文献数字化、手稿转录或教学材料解析。
- 政企与公共事业机构:政府档案部门、公共服务机构等需要合规且高效处理敏感文档的单位。
- 预算有限的中小企业与初创公司:需要高性能OCR能力但无法承担大型模型计算成本的项目团队。
©版权声明:如无特殊说明,本站所有内容均为Amassai.net 原创发布和所有。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。否则,我站将依法保留追究相关法律责任的权利。











.png)




评论 ( 0 )