






LongCat-Audio-Codec是什么
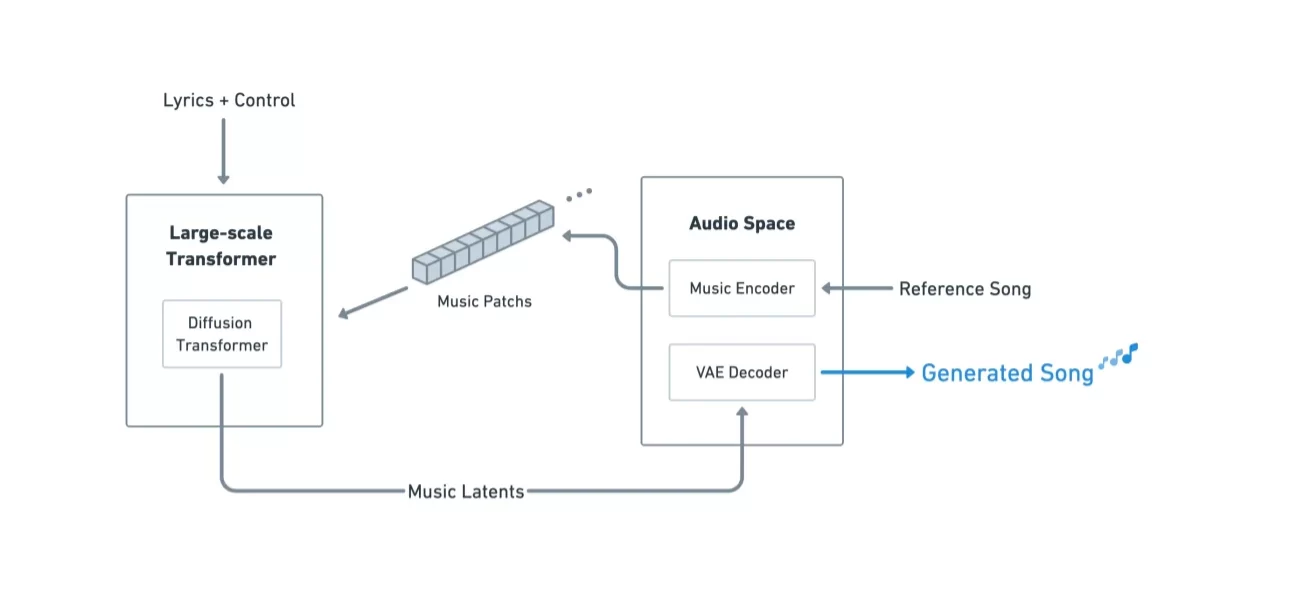
LongCat-Audio-Codec是由美团LongCat团队开发并开源的语音编解码技术方案。该方案专为语音大语言模型(Speech LLM)量身打造,运用语义与声学双Token同步提取的创新机制,能够同时捕捉语音的语义内容和声学特征,从而有效解决传统方案中语义与声学信息难以兼顾的难题。其低延迟的流式解码器支持即时交互,非常适合车载语音助手、实时翻译等需要快速响应的应用场景。该方案具备超低比特率下的高保真音频处理能力,并融合了超分辨率技术,即便在极低的比特率条件下也能实现高品质音频的重建。

LongCat-Audio-Codec的功能特色
-
语义与声学并行处理技术:采用语义和声学双 Token 同步提取方法,全面兼顾语音的语义含义和声学表现,显著提高语音处理的准确性与自然度。
-
低延迟流式解码性能:基于帧级增量处理架构,将解码延迟压缩至百毫秒范围,确保实时交互体验,完美适配车载语音助手和实时翻译等场景。
-
极低比特率高保真重建:即使在极低比特率条件下仍能实现高保真音频重建,同时集成超分辨率技术,有效提升音频的采样精度和自然感。
-
可定制的声学码本配置:支持根据不同应用需求调整声学码本数量,灵活适配少音色或多音色场景,提供个性化的音频处理方案。
-
多阶段训练优化策略:通过分阶段的训练过程,在保证高压缩率的同时实现高音质输出,满足多样化的应用需求。
-
完整的工具链支持:提供完整的Token生成与还原工具集,显著降低开发难度,助力语音大模型的快速落地应用。
LongCat-Audio-Codec的核心优势
-
创新性语义-声学双Token提取机制:首次实现语义信息和声学特征的同步提取,在保留语音语义理解的同时保留声学细节,突破传统方案中两者难以平衡的局限。
-
高效低延迟流式解码器:独创的帧级增量处理模式将解码延迟控制在百毫秒以内,大幅提升语音交互的即时性,满足车载助手、实时翻译等场景的严苛要求。
-
超低比特率高保真与超分辨率技术:在极低比特率环境下实现高保真音频重建,并将超分辨率处理融入解码流程,显著提升输出音频的采样率和自然度,增强语音细节表现。
-
动态声学码本调整能力:支持根据下游任务需求动态调整声学码本数量,灵活适配不同音色场景,提供更具适应性的解决方案。
-
分阶段训练优化体系:采用多阶段训练策略,分别针对高压缩率重构、高音质合成和个性化定制需求进行优化,全面提升模型性能表现。
LongCat-Audio-Codec官网是什么
- Github官方仓库:https://github.com/meituan-longcat/LongCat-Audio-Codec
- Hugging Face模型库:https://huggingface.co/meituan-longcat/LongCat-Audio-Codec
LongCat-Audio-Codec的适用人群
-
语音技术开发者:寻求高效音频处理工具以开发语音大语言模型(Speech LLM)及相关应用,如智能语音助手、跨语言翻译系统等。
-
人工智能研究者:从事语音识别、语音合成、语音交互等方向研究的学者,需要先进的音频编解码技术支持其研究工作。
-
产品研发团队:负责开发车载语音系统、智能语音设备、实时翻译软件等产品的团队,需要具备低延迟、高保真的音频解决方案。
-
音频处理工程师:在音频技术领域工作的专业人士,需要灵活的音频编解码工具优化音频处理流程和效果。
-
技术爱好者:对语音技术和音频处理有浓厚兴趣,希望探索和使用前沿的音频编解码技术进行项目开发或个人研究。
©版权声明:如无特殊说明,本站所有内容均为Amassai.net 原创发布和所有。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。否则,我站将依法保留追究相关法律责任的权利。
















评论 ( 0 )