






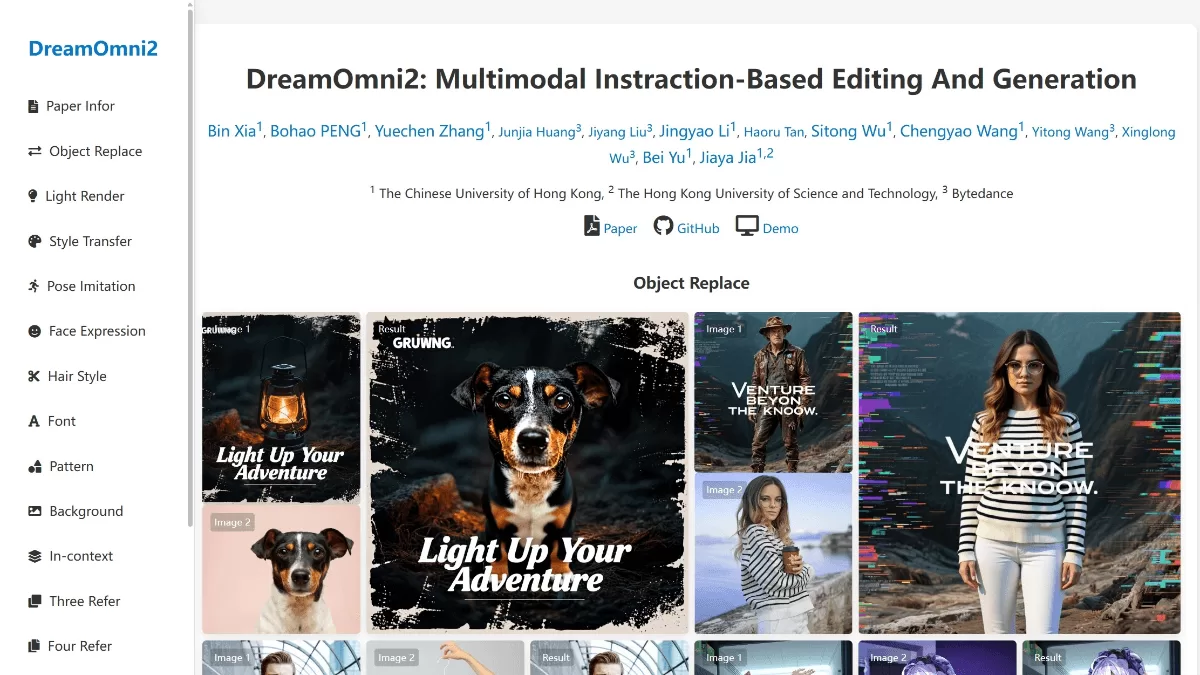
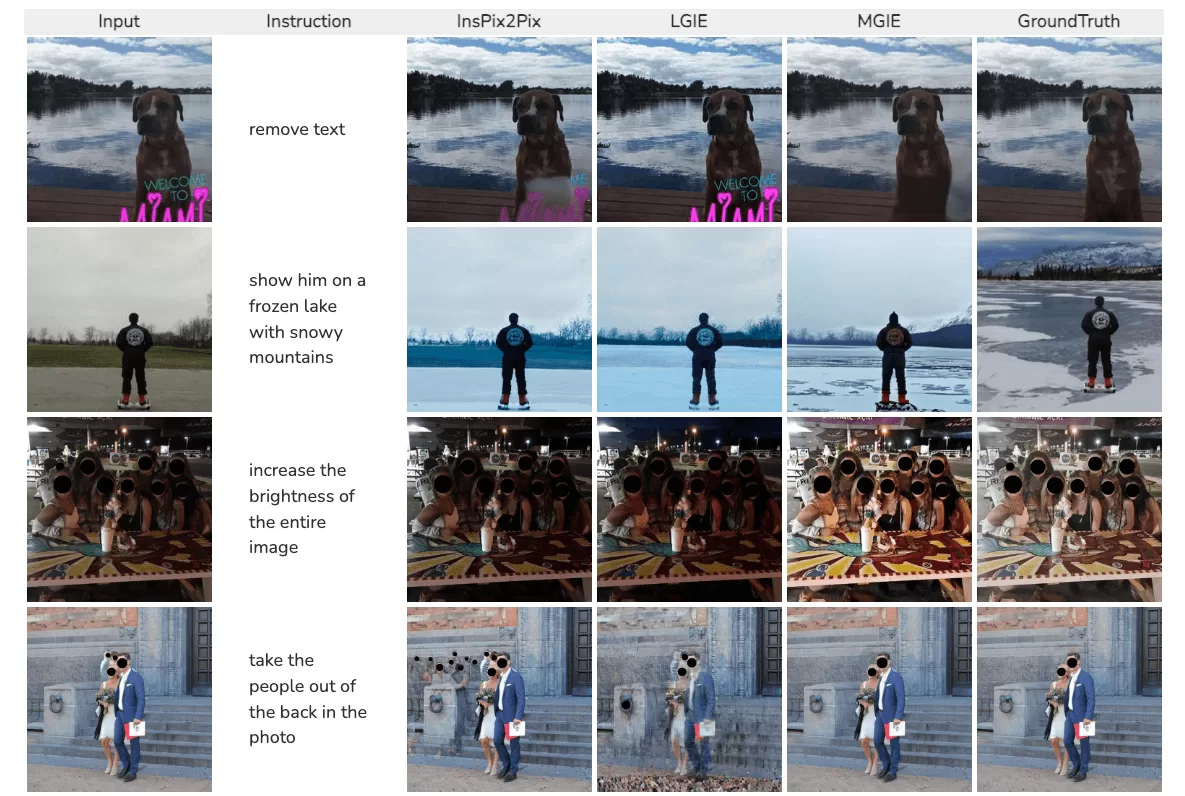
Open-o3 Video 的定义与作用
Open-o3 Video 是由北京大学与字节跳动共同研发的开源视频推理框架,其核心功能在于通过整合时间与空间维度证据来强化视频内容的理解能力。该模型通过精确标注关键证据的时间节点和位置边界,使系统能更深入地解析视频信息。在训练方法上,模型采用了分阶段优化策略:初期通过监督微调(SFT)完成基础学习,随后运用强化学习(RL)进行精细调优,从而确保输出结果的准确度与时空一致性。研究团队还构建了 STGR-CoT-30k 和 STGR-RL-36k 两大高精度数据集,为模型训练提供了充足的时空监督信息。

Open-o3 Video 的主要特性
-
时空证据融合推理:该模型通过明确标注关键时间点和边界框,将时空信息融入推理流程,显著增强了视频内容的解析精度和可解释性。
-
专业数据集支撑:研发团队创建了 STGR-CoT-30k 和 STGR-RL-36k 两个高价值数据集,为模型训练提供了丰富的时空监督信号,有效提升了模型的推理性能。
-
分阶段训练机制:结合监督微调(SFT)与强化学习(RL)的双重训练方法,通过多元奖励机制优化模型的推理准确度、时间同步性和空间分辨率。
-
突出性能表现:在 V-STAR 基准测试中,该模型的 mAM 和 mLGM 指标分别达到 35.5% 和 49.0%,显著超越其他同类模型,展现了卓越的视频推理能力。
-
开放共享特性:项目代码及模型已在 GitHub 和 Hugging Face 平台开放,为学术界和工业界提供便捷的访问和使用渠道,促进视频理解技术的普及应用。
Open-o3 Video 的核心优势
-
时空信息整合:模型在推理过程中明确标注关键时间戳和边界框,将时空数据与推理逻辑深度整合,大幅提高了视频分析的准确性和透明度。
-
高精度数据集驱动:开发团队构建的 STGR-CoT-30k 和 STGR-RL-36k 数据集提供了标准化的时空监督信号,为模型训练奠定了可靠的数据基础,确保模型在复杂场景下的稳定性。
-
双重优化训练:采用监督微调(SFT)和强化学习(RL)的协同训练方案,通过多样化奖励机制全面优化模型的推理精度、时间对齐效果和空间定位能力。
-
优异性能指标:在 V-STAR 基准测试中,Open-o3 Video 的关键性能指标(mAM 和 mLGM)显著领先于其他竞争模型,彰显了其在视频推理领域的领先地位。
-
多模态处理能力:基于强大的多模态基础模型(如 Qwen3-VL-8B),该框架能有效处理视频中的文本、图像和时间序列信息,实现更精准的多模态推理。
Open-o3 Video 的官方资源
- 项目官网:https://marinero4972.github.io/projects/Open-o3-Video/
- Github代码库:https://github.com/marinero4972/Open-o3-Video
- HuggingFace模型库:https://huggingface.co/marinero4972/Open-o3-Video/tree/main
- arXiv技术文档:https://arxiv.org/pdf/2510.20579
Open-o3 Video 的目标用户
-
AI 研究人员:专注于视频理解、多模态学习及自然语言处理领域的科研人员,可利用该模型进行创新性研究和算法改进。
-
计算机视觉工程师:从事视频处理、目标识别和视频内容生成的工程技术人员,能借助此模型提升项目开发效率和性能表现。
-
数据分析师:需要处理大规模视频数据的专业人士,可通过该模型获得更可靠的视频内容分析结果。
-
高校教育工作者:计算机科学、人工智能相关专业的教师和学生,可将其作为教学研究工具,探索视频理解领域的最新进展。
-
企业研发团队:在视频制作、智能监控、自动驾驶等领域的研发团队,可将模型应用于实际业务场景,增强产品技术竞争力。
©版权声明:如无特殊说明,本站所有内容均为Amassai.net 原创发布和所有。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。否则,我站将依法保留追究相关法律责任的权利。















评论 ( 0 )