






OmniVinci的概述介绍
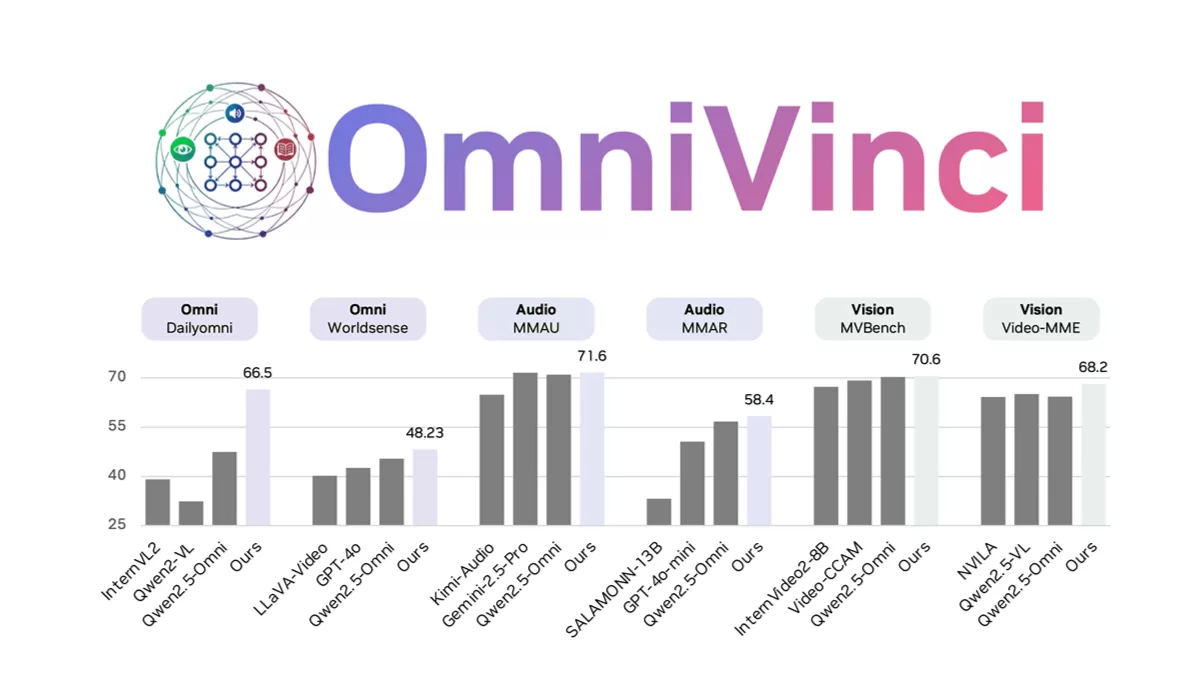
OmniVinci 是由 NVIDIA 研发的一款开源全模态大型语言模型,致力于解决多模态模型中常见的模态割裂难题。该模型通过架构创新和数据处理优化,显著提升了视觉、音频与文本信息的融合能力。OmniVinci 采用了先进的 OmniAlignNet 技术强化视觉和音频嵌入的对齐效果,并利用时间嵌入分组机制捕捉相对时间对齐关系,同时借助约束旋转时间嵌入编码绝对时间信息。在训练方面,该模型通过数据合成和优化的数据分布策略,大量生成单模态及全模态对话样本,从而提升训练质量。其两阶段训练流程先完成单模态训练,再进行全模态联合训练,有效整合多模态理解能力。根据基准测试结果,OmniVinci 在 DailyOmni 上的表现比 Qwen2.5-Omni 高出 19.05 分,且显著降低了训练所需的标记量。目前已在医疗 CT 影像分析和半导体器件检测等领域得到应用,展现了卓越的多模态处理能力。
OmniVinci的核心功能特性
-
跨模态信息处理:能够同时分析视觉、音频和文本数据,实现跨模态的信息整合与推理,例如可根据视频内容自动生成包含视听信息的详细描述。
-
创新模型设计:运用 OmniAlignNet 强化视觉与音频特征的匹配度,通过时间嵌入分组机制捕捉相对时间关系,并采用约束旋转时间嵌入技术编码绝对时间信息,从而增强模型对多模态信号的综合理解能力。
-
数据优化策略:通过数据合成和精心规划的数据分布方法,大量生成单模态和全模态对话样本,优化训练数据集,显著提升模型的泛化性能。
-
分阶段训练方法:采用先单模态后全模态的两阶段训练策略,先分别培养视觉和音频处理能力,再整合这些能力实现跨模态理解,有效增强模型的多模态推理性能。
-
高效训练机制:仅需 0.2 万亿训练标记量即可达到优异表现,相比其他模型大幅降低了训练资源需求。
OmniVinci的主要技术优势
-
卓越的多模态整合能力:能够同时处理视觉、音频和文本等多种模态信息,实现跨模态的信息理解与推理。
-
高效训练体系:采用分阶段训练方法,先进行单模态训练再进行全模态联合训练,有效整合多模态理解能力,同时显著降低训练资源消耗。
-
创新架构设计:通过 OmniAlignNet、时间嵌入分组和约束旋转时间嵌入等技术创新,强化视觉和音频嵌入的匹配效果,提升模型对多模态信号的理解程度。
-
数据优化方案:通过数据合成和精心设计的数据分布策略,大量生成高质量的单模态和全模态对话样本,优化训练数据,增强模型的泛化能力。
-
优异性能表现:在 DailyOmni、MMAR 和 Video-MME 等多个基准测试中表现突出,显著超越其他模型,且训练标记量大幅减少。
OmniVinci官方资源介绍
- 项目官方网站:https://nvlabs.github.io/OmniVinci/
- GitHub代码库:https://github.com/NVlabs/OmniVinci
- HuggingFace模型库:https://huggingface.co/nvidia/omnivinci
- arXiv技术论文:https://arxiv.org/pdf/2510.15870
OmniVinci的目标用户群体
-
人工智能研究者:对多模态学习、大型语言模型和跨模态理解有研究需求的学者,可使用 OmniVinci 探索新的研究方向和技术突破。
-
机器学习工程师:从事多模态应用开发的工程师,可通过 OmniVinci 提升模型性能,应用于实际项目开发中。
-
医疗领域专家:如放射科医生和医学研究人员,可借助 OmniVinci 的多模态理解能力,更精准地分析医学影像和相关数据。
-
工业自动化技术人员:在智能制造领域,利用 OmniVinci 的视觉和音频处理能力,提高设备检测和品质控制的效率。
-
机器人系统开发者:开发智能机器人系统的工程师,可利用 OmniVinci 增强机器人对环境的感知和理解能力。
-
数据分析师:对大规模数据处理和多模态数据分析有需求的数据分析师,可用 OmniVinci 提高数据处理效率和分析准确性。

©版权声明:如无特殊说明,本站所有内容均为Amassai.net 原创发布和所有。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。否则,我站将依法保留追究相关法律责任的权利。














.png)



评论 ( 0 )