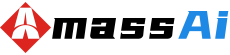







DiaMoE-TTS是什么技术
DiaMoE-TTS是由清华大学与巨人网络共同研发并开源的一款多方言语音合成系统,该框架以国际音标(IPA)为技术基础,专门针对方言数据不足、正字法标准不一以及音系变化复杂等挑战进行优化。通过采用统一的IPA前端进行音素标准化处理,有效消除了不同方言间的差异,并运用方言感知的Mixture-of-Experts(MoE)架构,让不同的专家网络分别负责学习各类方言的独特特征,从而精准保留每种方言的音色与韵律特质。该框架在F5-TTS平台的基础上进行了创新,引入了低秩适配器(LoRA)和条件适配器技术,实现了参数高效的方言迁移功能,用户只需微调少量参数即可完成方言的扩展。由于完全基于开源数据集进行训练,无需依赖昂贵的人工标注语音,因此大大降低了技术应用的门槛。实验数据显示,DiaMoE-TTS能够生成既自然又富有表现力的语音,即便在仅使用数小时数据的情况下,也能对未见过的新方言以及专业领域(例如京剧)实现零样本学习效果。目前该系统已支持11种汉语方言和普通话,未来计划扩展至欧洲语言。
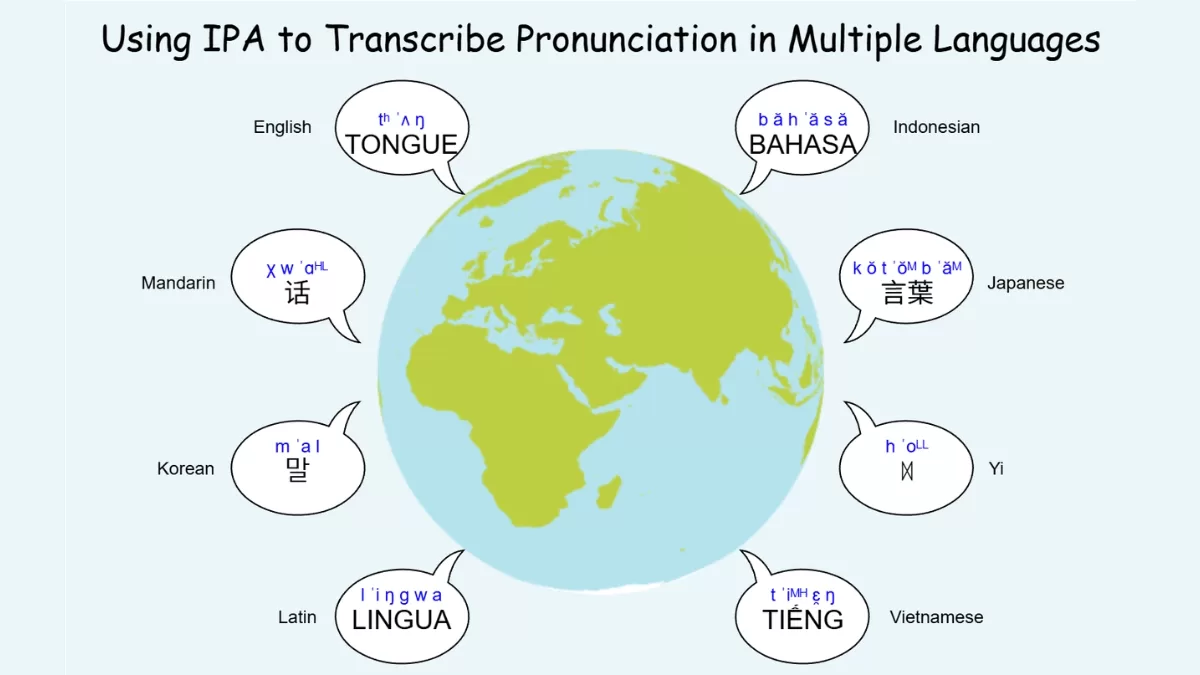
DiaMoE-TTS的主要特性
-
标准化的IPA输入系统:基于国际音标(IPA)构建可扩展的音素库,支持多种语言和方言的音素标注,有效统一不同方言的建模标准,提升模型的泛化性能。
-
智能方言MoE架构:采用方言感知的专家混合(MoE)网络设计,不同专家模块分别专精于特定方言特征的学习,通过动态路由机制智能选择最适配的专家,完整保留各地方言的独有音质与节奏感。
-
高效低资源适配:实施参数高效的迁移方案,仅需少量参数调整即可完成方言扩展,主干网络与MoE模块保持冻结状态,防止已有知识流失,实现新方言的快速适配。
-
分阶段训练流程:包含IPA迁移初始化、多方言联合学习、方言专家强化和低资源快速适配等步骤,逐步增强模型性能并适应多样化的方言特征。
-
开放数据训练模式:完全依托开源的语音识别(ASR)数据集进行训练,无需投入大量成本进行人工语音标注,降低技术使用门槛,支持基于开放数据的语音合成应用。
-
卓越泛化性能:即使在资源有限的方言中也能保持高水平的发音准确度,例如客家话的准确率可达91.7%,并能对未见过的新方言和专业领域(如京剧)实现零样本学习。
-
广泛适用场景:支持多种汉语方言及普通话的语音生成,可扩展至欧洲语言,适用于方言保护、文化创作等领域,为方言传承和文化产业发展提供技术支撑。
-
完整开发工具:提供训练与推理脚本、预训练模型以及开源数据集的IPA前端工具,方便用户快速部署和应用,加速语音合成技术的研发进程。
DiaMoE-TTS的核心优势
-
开源数据驱动:完全基于开源数据集进行训练,无需昂贵的人工语音标注,显著降低技术门槛与成本。
-
卓越泛化能力:在资源有限的方言中仍能实现高发音准确率,对未见过的新方言和专业领域(如京剧)可实现零样本性能表现。
-
语言多样性支持:支持多种汉语方言及普通话,未来可扩展至欧洲语言,为方言保护与语言多样性保护提供有力技术支持。
-
快速迁移技术:采用参数高效的迁移策略,仅需微调少量参数即可完成方言扩展,实现新方言的快速适配。
-
高品质语音输出:生成的语音自然流畅且富有表现力,实验验证其在语音质量与表达力方面表现优异。
DiaMoE-TTS官方资源
- GitHub代码库:https://github.com/GiantAILab/DiaMoE-TTS
- HuggingFace模型库:https://huggingface.co/RICHARD12369/DiaMoE_TTS
- arXiv技术论文:https://www.arxiv.org/pdf/2509.22727
DiaMoE-TTS的目标用户
-
语言研究者:为汉语方言及其他语言的语音特征分析、音系演变研究提供高效工具,助力语言学领域的学术探索。
-
语音技术开发者:提供开源框架和预训练模型,帮助开发者快速构建和优化多方言语音合成系统。
-
方言保护专家:支持方言保护项目,通过语音合成技术记录和传承濒危方言,促进语言多样性保护。
-
文化内容创作者:在影视、广播、游戏等领域,可用于制作具有地方特色的语音内容,增强文化表现力。
-
教育工作者:可用于开发方言教学资源,帮助学生学习和了解不同方言,丰富语言教育形式。
-
技术探索者:对语音合成、人工智能技术感兴趣的个人,可通过开源代码和文档进行学习和实践探索。
©版权声明:如无特殊说明,本站所有内容均为Amassai.net 原创发布和所有。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。否则,我站将依法保留追究相关法律责任的权利。













评论 ( 0 )