






DeepSeek-OCR 是什么
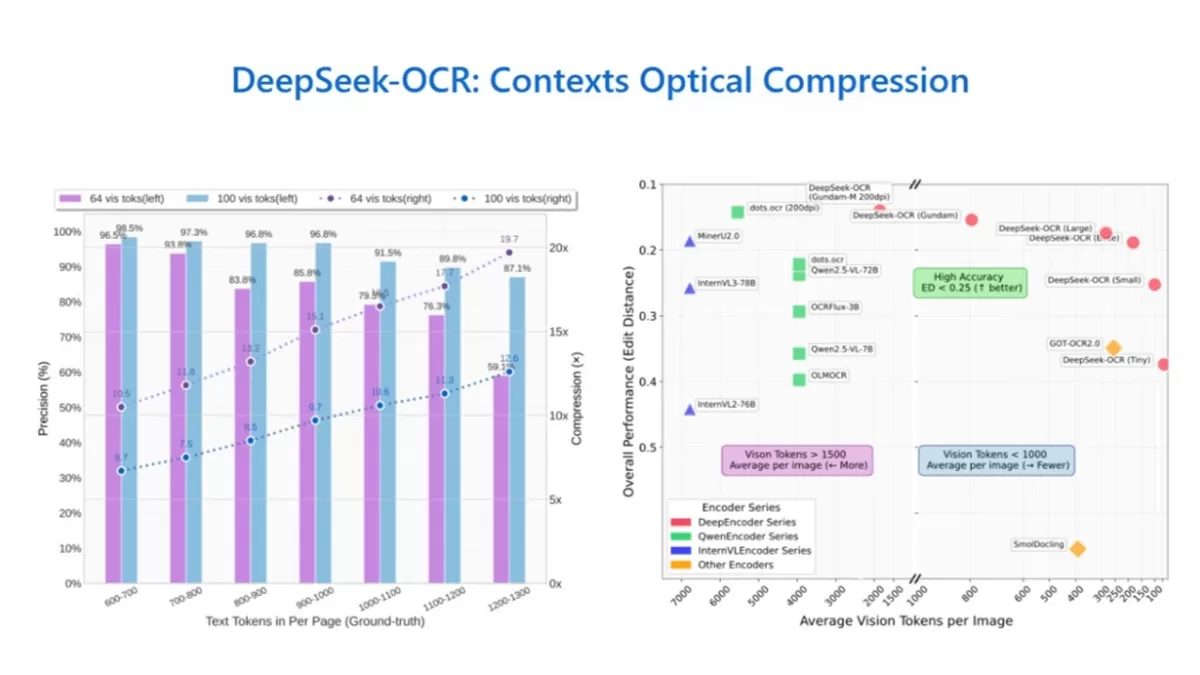
DeepSeek-OCR 是由 DeepSeek 团队开发并开源的一款创新性光学字符识别(OCR)系统,该系统运用了独特的“上下文光学压缩”方法,将文本内容转化为图像数据,再通过视觉 token 技术进行高效压缩与解码,从而实现长篇文档的快速处理。其技术亮点在于:具备 10 倍压缩下 97% 的识别精度、支持视觉与语言信息的联合分析、兼容多种文档格式(包括 JPG、PNG、PDF 等)及多语言环境、采用端到端的视觉语言模型(VLM)架构。该技术可广泛应用于长文本解析、复杂文档处理、多语言识别等领域,并支持在本地环境中部署使用。性能表现尤为突出:单张 A100-40G 显卡即可支持每日超 20 万页的训练数据处理量;移动设备上可实现每秒 15 帧的实时识别,延迟控制在 100 毫秒以内;在复杂场景中,识别准确率高达 98.7%,较行业基准提升 6.4 个百分点。项目已完全开源,代码及模型权重公开可用。
DeepSeek-OCR 的核心功能
-
创新性上下文光学压缩:该技术将文本信息转化为可视化图像,并借助视觉 token 进行智能压缩和解码,特别适合处理大量文本数据,压缩 10 倍时仍能保持 97% 的识别准确率。
-
视觉-语言协同处理:通过融合图像中的视觉特征(如位置布局、图形元素)与语言模型的理解能力,能够精准捕捉文档的语义内容和版面结构,显著提升复杂文档的识别效果。
-
全格式多语言兼容:全面支持 JPG、PNG、PDF 等主流图像格式,以及 100 多种语言文字的识别,对手写体、混合排版(图文混排)、表格数据等复杂文档同样表现出色。
-
高压缩比与高精度平衡:在 10 倍压缩比例下,OCR 识别准确率可达 97%;即使压缩比例提升至 20 倍,模型仍能保持约 60% 的准确率,有效平衡了存储效率与识别质量。
-
端到端 VLM 架构设计:系统采用 DeepEncoder 图像特征提取器与 DeepSeek3B-MoE 解码器组合,编码器负责图像特征提取、token 化及视觉表示压缩,解码器则基于图像 token 和指令提示生成最终识别结果。
-
多元化应用场景:可将数千字长文档压缩成单张图片,以极低成本实现 97% 的精准还原,为大型语言模型提供高效的上下文扩展方案;能够识别表格数据、财务报表中的关键信息,甚至解析化学分子式、数学公式等特殊内容;支持包括中文、英文在内的 100 多种语言;提供本地化部署选项,确保敏感文档数据不外传。
-
卓越性能表现:单张 A100-40G 显卡即可支持每日 20 万页以上的训练数据处理;移动端设备可实现每秒 15 帧的实时识别,响应延迟小于 100 毫秒;通过多尺度动态特征融合模块与上下文感知解码机制,复杂场景下的识别准确率高达 98.7%,领先行业平均水平 6.4 个百分点。
DeepSeek-OCR 的主要优势
-
高效能上下文压缩技术:通过文本图像化转换和视觉 token 处理,在实现 10 倍压缩时仍保持 97% 的识别精度,压缩 20 倍时准确率仍达 60%,有效解决了长文本处理效率难题。
-
深度视觉语言融合:整合图像中的视觉布局信息(如表格边界、图形位置)与语言模型的理解能力,不仅识别文字内容,更能精准把握文档的语义结构和版面特征,增强复杂文档的处理能力。
-
广泛兼容的格式与语言:支持 JPG、PNG、PDF 等多种图像格式及 100 多种语言文字,对手写体、混排文本、图表与文字混合文档的识别效果良好,适用范围广泛。
-
优异的性能指标:单张 A100-40G 显卡可支持每日 20 万页以上的训练数据处理;移动端设备可实现每秒 15 帧的实时识别,延迟低于 100 毫秒;复杂场景下识别准确率高达 98.7%,显著超越行业基准水平。
-
灵活的部署选项:支持在本地环境中部署使用,无需将敏感文档上传至第三方云服务,保障数据安全,同时满足不同用户对部署环境的需求。
DeepSeek-OCR 官方资源
- GitHub 代码库:https://github.com/deepseek-ai/DeepSeek-OCR
- HuggingFace 模型库:https://huggingface.co/deepseek-ai/DeepSeek-OCR
- 技术论文:https://github.com/deepseek-ai/DeepSeek-OCR/blob/main/DeepSeek_OCR_paper.pdf
DeepSeek-OCR 的目标用户
-
企业用户:适用于需要处理大量文档(如财务报表、合同、技术手册等)的场景,通过高效长文本处理和复杂文档识别功能,可显著提升工作效率并降低人力成本。
-
科研工作者:在学术研究中经常需要处理多语种文献、图表和公式等复杂内容,DeepSeek-OCR 的多语言支持与精准识别能力可为科研工作提供有力支持。
-
教育工作者:可用于教学资料的整理和数字化,如课件制作、试卷分析等,其对手写体识别和多格式支持功能能满足教学需求。
-
技术开发者:开源的代码和模型权重,便于开发者集成到自有项目中,构建定制化的 OCR 应用,拓展应用场景。
-
个人用户:对于需要快速提取文档内容、整理笔记、翻译外文资料等日常办公和学习场景,DeepSeek-OCR 提供了高效便捷的解决方案,可显著提升个人工作效率。

©版权声明:如无特殊说明,本站所有内容均为Amassai.net 原创发布和所有。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。否则,我站将依法保留追究相关法律责任的权利。














评论 ( 0 )